Management Summary
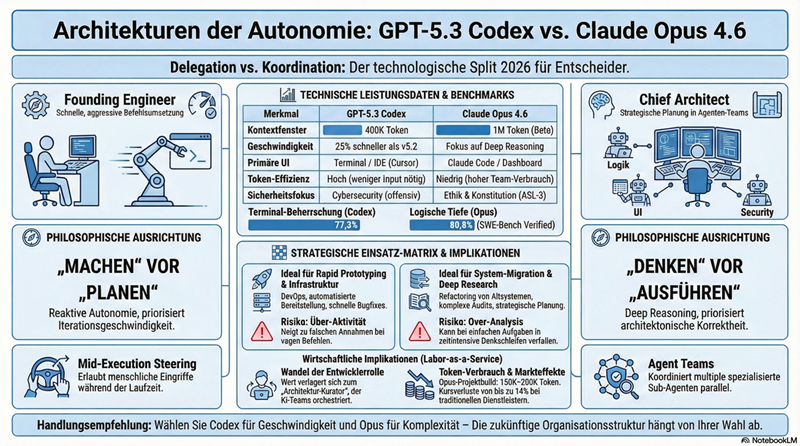
Hinter ähnlichen Benchmark-Ergebnissen verbergen sich gegensätzliche Designphilosophien: OpenAIs Codex-Ansatz [1] setzt auf Delegation an spezialisierte Sub-Agenten, Anthropics Opus-Ansatz [2] auf Koordination im Dialog mit dem Nutzer. Standard-Benchmarks wie SWE-bench [3] und GAIA [4] bilden diesen Unterschied nur unzureichend ab – relevant wird er erst in Zuverlässigkeit, Selbstkorrektur und Sicherheitskontext. Für Unternehmen ist die Architekturwahl daher kein technisches, sondern ein Governance-Thema: Wie viel Autonomie ist in welchem Kontext zumutbar? Die Antwort wird zunehmend hybrid lauten.
Für wen relevant?
CIO/CTO und IT-Architekten; Compliance- und Risk-Verantwortliche; KI-Strategie- und Innovationsteams; Produktverantwortliche für Agentic-AI-Anwendungen; Vorstände in regulierten Branchen (Healthcare, Finanzen, öffentliche Verwaltung).
Drei Kernaussagen
- Delegation und Koordination sind unterschiedliche Philosophien. Beide haben Berechtigung – aber für unterschiedliche Aufgabenklassen. Wer das mischt, ohne den Unterschied zu kennen, baut Fehler ein.
- Benchmarks lesen, aber nicht glauben. SWE-bench-Werte unterscheiden sich oft im einstelligen Prozentbereich; entscheidend ist Verhalten bei Mehrdeutigkeit, Fehlerrekonvaleszenz und langen Aufgabenketten.
- Architekturwahl ist Governance-Wahl. In regulierten Bereichen ist Transparenz wichtiger als Geschwindigkeit. Diese Prämisse muss Vorgabe sein, nicht Nebenfolge.
Die aktuelle Generation großer Sprachmodelle hat eine neue Evolutionsstufe erreicht: den Schritt vom Werkzeug zum Agenten. Sowohl OpenAIs GPT-5.3 Codex als auch Anthropics Claude Opus 4.6 können eigenständig Aufgaben planen, Werkzeuge nutzen und mehrstufige Workflows orchestrieren. Doch hinter ähnlichen Ergebnissen verbergen sich grundverschiedene Architekturen und Designphilosophien. Das Verständnis dieser Unterschiede ist entscheidend für jeden, der Agentic AI im Unternehmenskontext einsetzen will.
Delegation versus Koordination
OpenAI verfolgt mit Codex einen Delegationsansatz: Ein zentrales Modell verteilt Teilaufgaben an spezialisierte Sub-Agenten, die relativ autonom operieren und ihre Ergebnisse zurückliefern. Das ermöglicht hohe Parallelität und schnelle Abarbeitung komplexer Workflows. Anthropics Opus 4.6 setzt dagegen auf einen Koordinationsansatz, bei dem der Agent stärker in einem Dialog mit dem Nutzer bleibt und Rückfragen stellt, bevor er kritische Entscheidungen trifft. Diese Philosophie priorisiert Transparenz und Kontrollierbarkeit über reine Geschwindigkeit – ein Unterschied, der in regulierten Branchen wie dem Gesundheitswesen oder der Finanzindustrie erheblich ins Gewicht fallen kann.
Benchmarks und ihre Grenzen
In standardisierten Benchmarks wie SWE-bench [3], HumanEval und GAIA [4] liefern sich beide Modelle ein Kopf-an-Kopf-Rennen, wobei je nach Aufgabentyp mal das eine, mal das andere System vorne liegt. Doch Benchmarks bilden die Realität unternehmerischer Anforderungen nur bedingt ab. In der Praxis zählen Faktoren wie Zuverlässigkeit bei langen Aufgabenketten, Umgang mit Mehrdeutigkeit, die Fähigkeit zur Selbstkorrektur und das Verhalten bei unvorhergesehenen Fehlern. Hier zeigen sich die architekturellen Unterschiede deutlicher: Das Delegationsmodell skaliert besser bei klar definierten Aufgaben, während das Koordinationsmodell bei ambigen Anforderungen und sicherheitskritischen Kontexten Stärken zeigt.
Strategische Implikationen für Unternehmen
Für Entscheider ist die Wahl zwischen den Architekturen keine rein technische Frage. Sie betrifft Governance, Compliance und die Frage, wie viel Autonomie man einer KI in welchem Kontext zugestehen will. Unternehmen, die Agentic AI erfolgreich einsetzen wollen, sollten beide Paradigmen verstehen und je nach Anwendungsfall bewusst wählen. Die Zukunft gehört voraussichtlich hybriden Architekturen, die Delegation und Koordination situativ kombinieren – doch dafür braucht es intern aufgebaute Kompetenz, nicht bloß eingekaufte Lizenzen.
Quellen
Hersteller-Dokumentation und Benchmark-Paper. Abruf: 27.04.2026.
- OpenAI: Codex – AI Software Engineering Agent. openai.com
- Anthropic: Claude Models – Capabilities and Engineering. anthropic.com
- Jimenez, C.; Yang, J.; Wettig, A. et al.: SWE-bench: Can Language Models Resolve Real-World GitHub Issues? ICLR 2024. swebench.com
- Mialon, G.; Fourrier, C.; Swift, C. et al.: GAIA: A Benchmark for General AI Assistants. arXiv:2311.12983, 2023. arxiv.org
- Anthropic Engineering: Building effective agents. anthropic.com
Weiterlesen im Themenfeld KI-Agenten
Analysen wie diese in den Posteingang?
Der Newsletter bündelt die wichtigsten Beiträge des Monats. Kein Spam, kein Tracking.
Newsletter abonnieren